Semantic Skills — Skill Pre-Loading That Keeps Prompt Caching Intact
The jit-skills plugin cut Hermes Agent's system prompt from 4,200 tokens to 226 by replacing the full skill listing with a search_skills tool. That saved 95% on the system prompt. But it had a catch: the agent had to call the tool on the first turn of every task, burning 1,500 to 3,000 tokens. And if the top-match skill were pre-loaded into the system prompt, it would break exact-prefix prompt caching.
semantic-skills v2 fixes both problems. It pre-loads the best-matching skill into the user message via a pre_gateway_dispatch hook — no tool call needed, and the system prompt stays byte-identical across turns.
The Architecture Change
In v1 (jit-skills), skill delivery was reactive:
User message → agent calls search_skills → tool response → agent reads skill
This added one tool-call turn to every new task. On GPT-5.5 or Claude, that turn costs 1,500 to 3,000 tokens each time.
In v2 (semantic-skills), skill delivery is pre-loaded at the gateway level:
User message arrives at gateway
→ pre_gateway_dispatch hook fires (before auth, before agent dispatch)
→ embed query against 407 skill vectors
→ top match above 0.30 threshold → rewrite message with skill prepended
→ LLM sees: [stable 226-token system prompt] [user msg: skill + query]
The pre_gateway_dispatch hook fires at the gateway layer — before authentication, before platform pairing, before the agent even wakes up. It embeds the user's query, finds the top match, and rewrites the incoming message text to include the skill content at the top. The system prompt is never touched.
This is a better injection point than pre_llm_call for two reasons. First, it fires earlier in the pipeline, so the skill content is baked into the raw message before any downstream processing. Second, it returns {"action": "rewrite", "text": "..."} to replace the message text directly, rather than injecting ephemeral context that the agent loop has to manage.
| Feature | jit-skills v1 | semantic-skills v2 |
|---|---|---|
| Skill delivery | Agent calls search_skills tool | Pre-loaded via pre_gateway_dispatch hook |
| First-turn tool call | Yes (1,500-3,000 tokens) | Eliminated |
| System prompt | 226 tokens, cache-friendly | 226 tokens, cache-friendly |
| Injection point | Tool result (messages array) | pre_gateway_dispatch (gateway layer, before auth) |
| Session cache | None | Skips re-injection on follow-up turns |
| Tokens saved (vs full) | ~4,000 | ~5,500-7,000 |
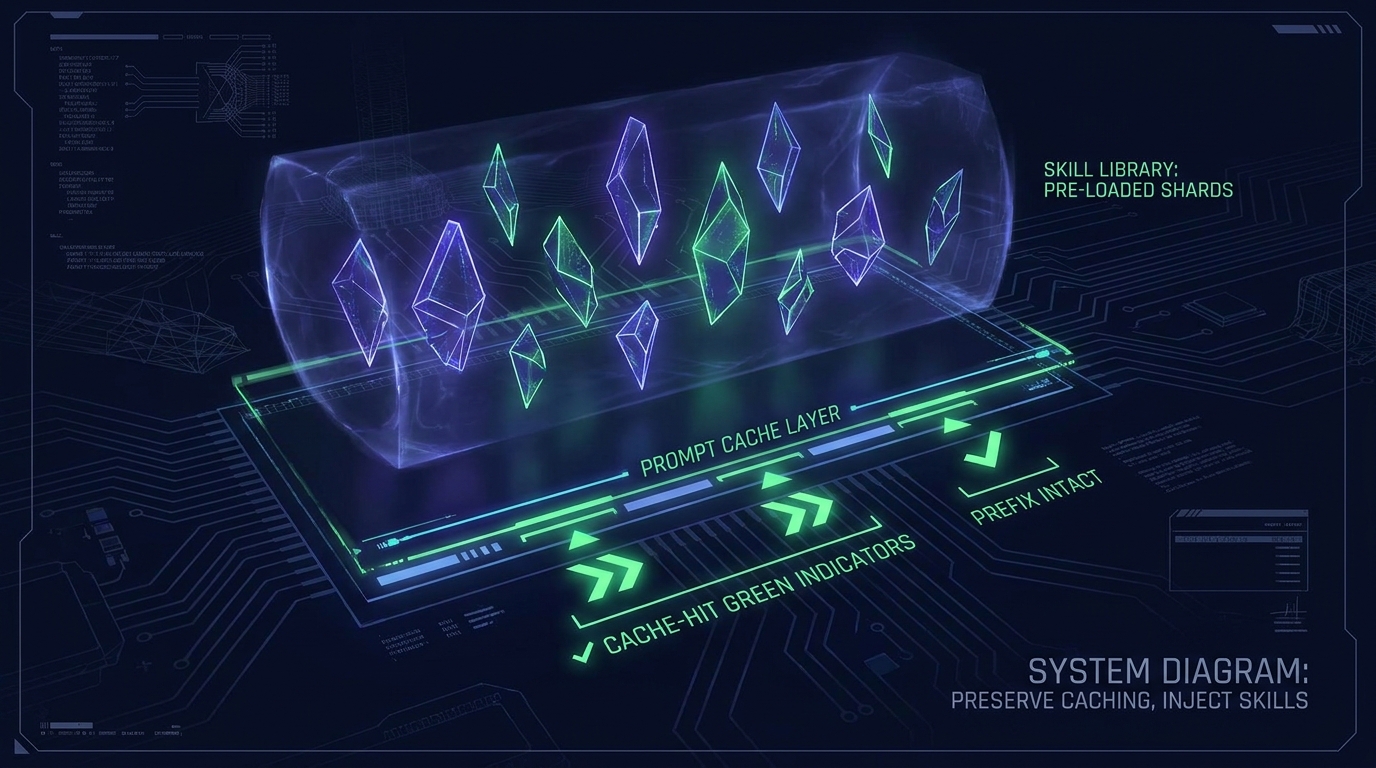
Why This Matters for Prompt Caching
Prompt caching on every major provider (Anthropic, OpenAI, DeepSeek) uses exact-prefix matching. If the system prompt changes by even one byte between turns, the entire cache invalidates.
The v1 plugin had a tension: if you pre-loaded a skill into the system prompt, it would break the cache. The only safe choice was to make the agent call the search_skills tool and accept the tool-call overhead.
v2 resolves this by injecting into the user message, not the system prompt. The system prompt stays at 226 tokens — identical across every turn. The per-turn skill content goes into the user message, which is always part of the uncached tail. The cache contract is preserved.
This is the same pattern Claude Code uses internally: stable tool stubs and system instructions at the top, dynamic content appended to the messages array.
The pre_gateway_dispatch Hook
The hook fires at the gateway level, before auth, pairing, or agent dispatch. It embeds the incoming message, finds the top match, and rewrites the message text:
def on_pre_gateway_dispatch(event, gateway, session_store, **kwargs):
text = event.text
if len(text.split()) < 3: # skip short queries
return None
# Embed query against pre-built skill index
store = lazy_import_embedding_store()
query_embedding = store.embed_text(text)
best_score, best_meta = rank_by_cosine_similarity(query_embedding, embeddings)
if best_score < 0.30: # threshold
return None
# Read full SKILL.md content
skill_content = store.read_skill_content(best_meta["path"])
# Avoid re-injecting the same skill on follow-up turns
session_key = event.source.chat_id or event.source.user_id
if _SESSION_CACHE.get(session_key) == best_meta["name"]:
return None
_SESSION_CACHE[session_key] = best_meta["name"]
rewritten = (
f"Relevant skill (pre-loaded, score {best_score:.2f}): {best_meta['name']}\n"
f"{'─' * 60}\n"
f"{skill_content}\n"
f"{'─' * 60}\n\n"
f"if this skill is insufficient, call search_skills for additional matches.\n\n"
f"{text}"
)
return {"action": "rewrite", "text": rewritten}
The hook has three guardrails:
- Short queries (< 3 words) are skipped — single-word responses don't need skills
- Score threshold of 0.30 — below this, the query is too ambiguous for reliable pre-loading
- Session cache — the same skill is not re-injected on follow-up turns in the same session
The return value {"action": "rewrite", "text": "..."} tells the gateway to replace the raw message text before it reaches the agent loop. If the hook returns None, the message passes through unchanged and the agent can still use the search_skills tool as a fallback.
Token Savings
The total savings vs full mode (all 407+ skills listed in the system prompt):
| Source | Full Mode | JIT v1 | Semantic v2 |
|---|---|---|---|
| System prompt | 4,200 | 226 | 226 |
| First-turn tool call | 0 | 1,500-3,000 | 0 |
| Total per session | 4,200 | 1,726-3,226 | 226 |
Per session, v2 saves an additional 1,500 to 3,000 tokens over v1 by eliminating the tool call. Across a typical Hermes session (39 turns[^1]), that compounds.
Installation
# Install the plugin
hermes plugins install underdown/semantic-skills --enable
# Build the embedding index
cd ~/.hermes/plugins/semantic-skills
python3 build_embeddings.py --backend litellm --force
# Enable semantic mode (also accepts "jit" for backward compatibility)
hermes config set skills.mode semantic
# Restart
hermes gateway restart
Migrating from jit-skills
If you are using the v1 jit-skills plugin:
hermes plugins uninstall jit-skills
hermes plugins install underdown/semantic-skills --enable
cd ~/.hermes/plugins/semantic-skills
python3 build_embeddings.py --backend litellm --force
hermes config set skills.mode semantic
hermes gateway restart
The search_skills tool remains available as a fallback. The embedding index format is compatible — no rebuild strictly required if the index already exists, but rebuilding with --force ensures the index covers any newly installed skills.
What It Does Not Do
The pre-load hook injects exactly one skill — the top match above threshold. It does not rank multiple candidates or inject ranked lists. If the pre-loaded skill is insufficient, the agent calls search_skills to find alternatives. This is by design: injecting multiple skills would bloat the user message and undermine the token savings.
The hook does not modify the system prompt. This is a hard constraint — pre_gateway_dispatch rewrites the incoming message text at the gateway layer. The system prompt is assembled later and cannot be touched by this hook.
Availability
GitHub: underdown/semantic-skills
The jit-skills plugin has been deprecated and its repository updated with migration instructions. Both skills.mode: "jit" and skills.mode: "semantic" are accepted by the source patch for backward compatibility.
[^1]: Per-turn average derived from Hermes Agent session DB analysis across 50+ sessions. A "turn" includes user message, assistant response, and all tool-call iterations in between.