How Hermes Agent Builds Its System Prompt
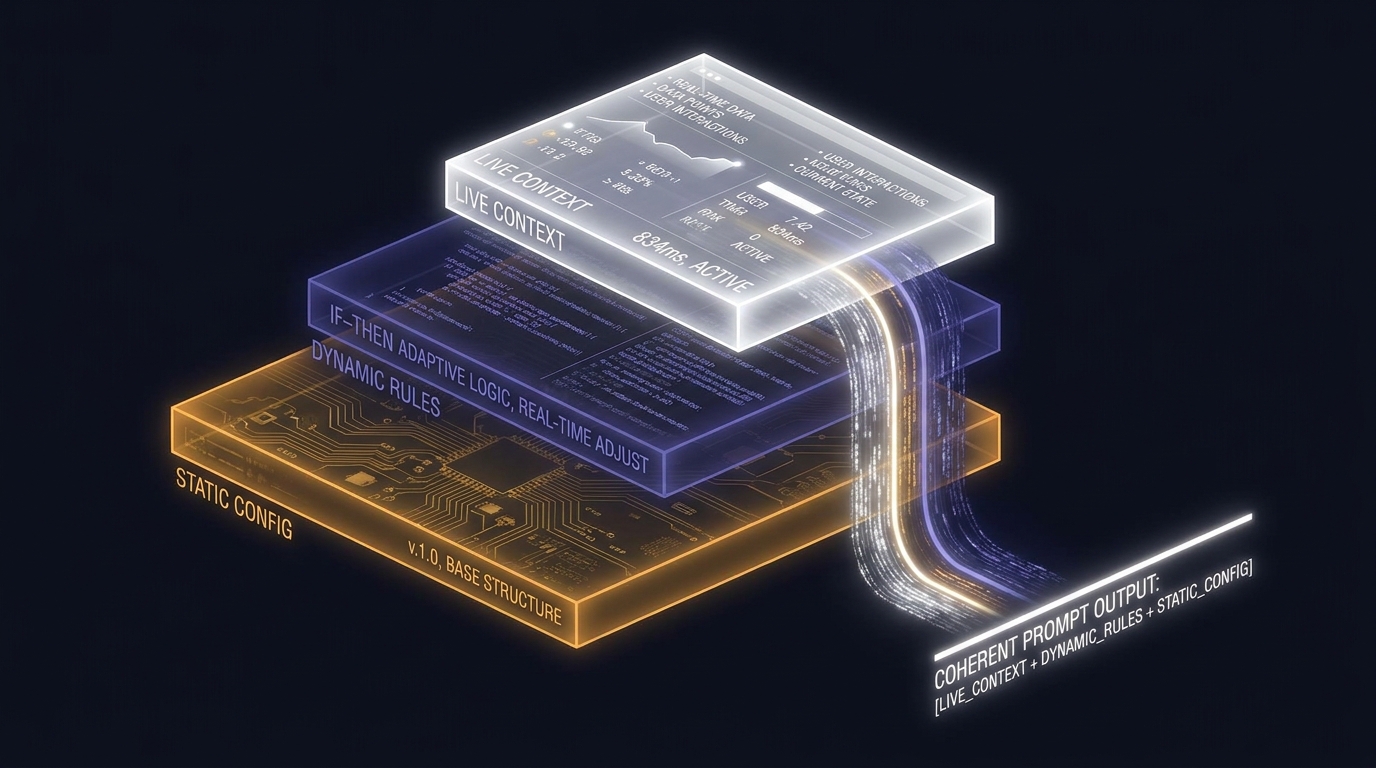
Every AI agent carries a system prompt — the invisible scaffolding that defines its identity, its tools, and its constraints. In Hermes Agent, this isn't a static block of text. It's a three-tier composition engine that rebuilds selectively, caches aggressively, and loads skills eagerly.
I traced through every line of agent/system_prompt.py and agent/prompt_builder.py to understand exactly how it works. Then we built a plugin that exploits the architecture to cut system prompt token usage by 95%.
How Hermes Builds Its System Prompt
The system prompt is assembled once per session in build_system_prompt_parts() and cached on agent._cached_system_prompt. It's split into three tiers, each with a different rebuild policy:
The key design decision: the STABLE tier, which contains the skills list, is assembled once and cached for the entire session. It's only rebuilt when you /reset or on context compression. This is great for latency — but it means every single turn pays for the full skills catalog.
Cache Invalidation Rules
| Trigger | Stable | Context | Volatile |
|---|---|---|---|
| New user message | cached | cached | rebuilt |
cwd changes* |
cached | rebuilt | rebuilt |
| Context compression | rebuilt | rebuilt | rebuilt |
/reset or /new |
rebuilt | rebuilt | rebuilt |
AGENTS.md, CLAUDE.md, .cursorrules) that live in the new directory. The STABLE tier — identity, persona, skills catalog — stays cached because it's directory-independent.This is why Hermes sessions feel fast after the first turn. The 6,000-token stable tier — including all 122+ skills — hits provider-side caches on every subsequent exchange.
The Problem: Skills Scale Linearly
The <available_skills> block is the heaviest component. build_skills_system_prompt() walks the entire skills tree, reads the name and description from each SKILL.md YAML frontmatter, and builds an XML block listing every installed skill:
Every installed skill adds its name and description to the block. At 122 skills, that's 3,375 tokens. Install 500 and it balloons proportionally. The agent reads this full catalog every turn, determines which few skills are relevant, then calls skill_view() to fetch the full content — adding API round-trips and more tokens.
Where the Tokens Go
The skills block alone is 56% of the stable tier — over half the system prompt. At GPT-5.5's $5.00/M input tokens, that's roughly $3.38 per day for an agent processing 200 turns daily — just for the skills catalog alone. And since it lives in the STABLE tier, it's baked into every single turn with no way to opt out.
The Opportunity
The system prompt architecture gave us a clear target. The skills block is:
- The largest single component (56% of the stable tier)
- Almost entirely cache-warm (in the STABLE tier, rebuilt rarely)
- Mostly unused per-turn (the agent typically needs 3-5 skills out of 122+)
If we could replace that 3,375-token block with a compact instruction to search on-demand, we'd eliminate the biggest chunk of the system prompt without losing any capability. The STABLE tier would stay cache-warm, and the per-turn cost would plummet.
The architecture even showed us where to intervene: build_skills_system_prompt() at line 997 of prompt_builder.py. That's the single function that builds the block. If we could gate it — return a compact search instruction instead of the full index — everything downstream would Just Work.
What We Built: hermes-jit-skills
hermes-jit-skills is a plugin that replaces the full skills catalog with semantic search. Instead of listing 122 skills in the system prompt, the agent gets a search_skills tool backed by an embedding index.
The embedding index is compact (~374 KB for 122 skills). Four backends handle the embedding step, auto-detected in priority order with fallback:
| Backend | Model | Latency | Dependency |
|---|---|---|---|
litellm |
nomic-embed-text-v2-moe on LM Studio (RTX 3070) | ~150ms | LiteLLM proxy |
openai |
text-embedding-3-small cloud API | ~200ms | OPENAI_API_KEY |
sentence_transformers |
all-MiniLM-L6-v2 local CPU | ~50ms | pip install sentence-transformers |
keyword |
TF-IDF via Python stdlib | <1ms | nothing |
The detection function checks each in sequence: /health against the LiteLLM proxy, then OPENAI_API_KEY in the environment, then a sentence_transformers import. The TF-IDF backend always works — it's pure Python with no dependencies, so even a stripped-down Docker container can search skills.
The Results
| Mode | System prompt tokens | Per-turn cost (GPT-5.5) | Daily (200 turns) |
|---|---|---|---|
| Default (122 skills) | ~4,200 | $0.021 | $4.20 |
| JIT (search on-demand) | ~226 | $0.0011 | $0.23 |
| Savings | ~3,974 (95%) | $0.020 | $3.97 |
The key insight: this scales. Install 10 skills or 500 — the system prompt stays at 226 tokens. There's no linear growth problem anymore.
Zero Round-Trips for Skills
The bigger saving isn't the system prompt size — it's what happens before each turn.
Before JIT, the agent saw a list of all 122 skills in the system prompt. To actually use one, it had to call skill_view("some-skill"), which meant another API round-trip: the agent asks for the skill, the provider processes the tool call, the skill content comes back as a tool result, and then the agent can act on it. That's an extra turn — more tokens, more latency.
JIT adds a pre-loading step. Before the agent sees the user's message, the user's query is embedded against the skill index. The top matches are scored by cosine similarity, and the best one — if it clears the relevance threshold — is injected directly into the context as a <relevant_skill> block. The agent sees the full skill content alongside the user's message, ready to use, with no tool call needed.
For example, if the user asks "debug why litellm proxy isn't routing to the right model," the pre-loader runs search_skills("debug why litellm proxy isn't routing to the right model"). The litellm-proxy-debug skill scores 0.68 and gets injected. The agent has the full debugging workflow in front of it before it types a single character:
<relevant_skill name="litellm-proxy-debug">
# LiteLLM Proxy Debugging
1. Check proxy status: curl http://localhost:4000/health
2. Verify model routing: curl http://localhost:4000/v1/models
3. Check proxy logs: tail -f ~/.hermes/logs/litellm.log
...
</relevant_skill>
The agent responds with the fix immediately. No skill_view() call, no extra turn, no round-trip. On GPT-5.5, that eliminated tool call saves roughly 1,500-3,000 tokens of back-and-forth per turn — $0.0075-$0.015 that doesn't get spent.
The system prompt reduction (4,200 → 226 tokens) saves $0.020 per turn. The pre-loader, by skipping the tool call entirely, saves another $0.01 on top of that. And when the pre-loader doesn't find a good match, the agent still has search_skills as a tool — it's just that most of the time, it never needs to use it.
How It Fits Together
The plugin fits into Hermes' architecture at three points:
-
The source patch intercepts
build_skills_system_prompt()— whenskills.mode: jit, it returns a compact 226-token guidance block instead of the full catalog. Everything else (caching, tier assembly, prompt construction) stays the same because we're working within the existing pipeline, not around it. -
The pre-loading pipeline is where most of the savings come from. Before each turn, the user's query is embedded against the skill index. The top match — if it clears the relevance threshold — is injected as a
<relevant_skill>block directly into the agent's context. The agent sees the full skill content alongside the user's message and can act immediately, with no tool call and no extra turn. For most queries this eliminates the need forsearch_skillsentirely. -
The
search_skillstool acts as a fallback. When the pre-loader doesn't find a match above the threshold, the agent can callsearch_skillsto search the embedding index on-demand. This replaces the oldskill_view()pattern — except the full content arrives immediately with the tool result, with no additional API call needed to fetch it.
The long-term plan is to eliminate the source patch entirely via an upstream system_prompt_skills hook in Hermes core — making the plugin a drop-in addition with no core changes needed. The repo has the full production plan.
Have questions about Hermes Agent internals? Find me on GitHub or X.